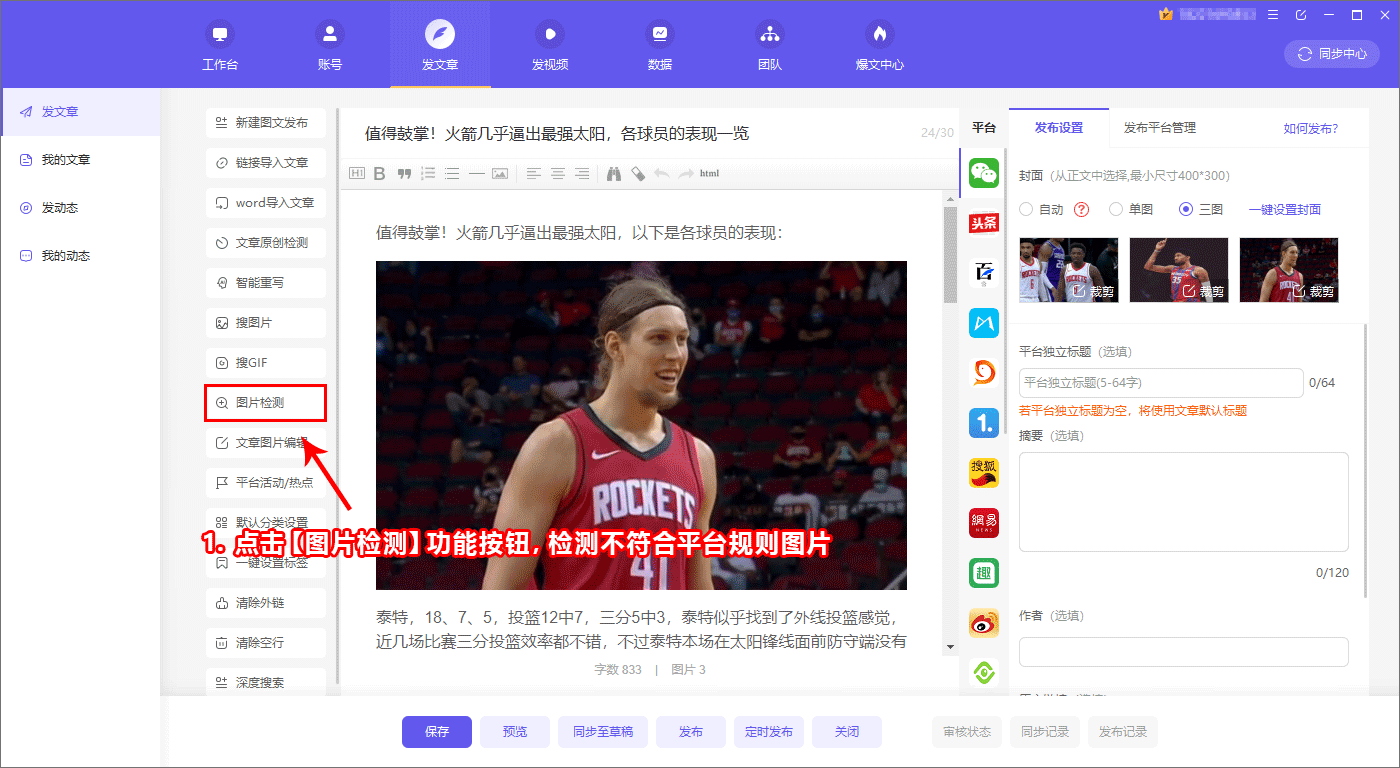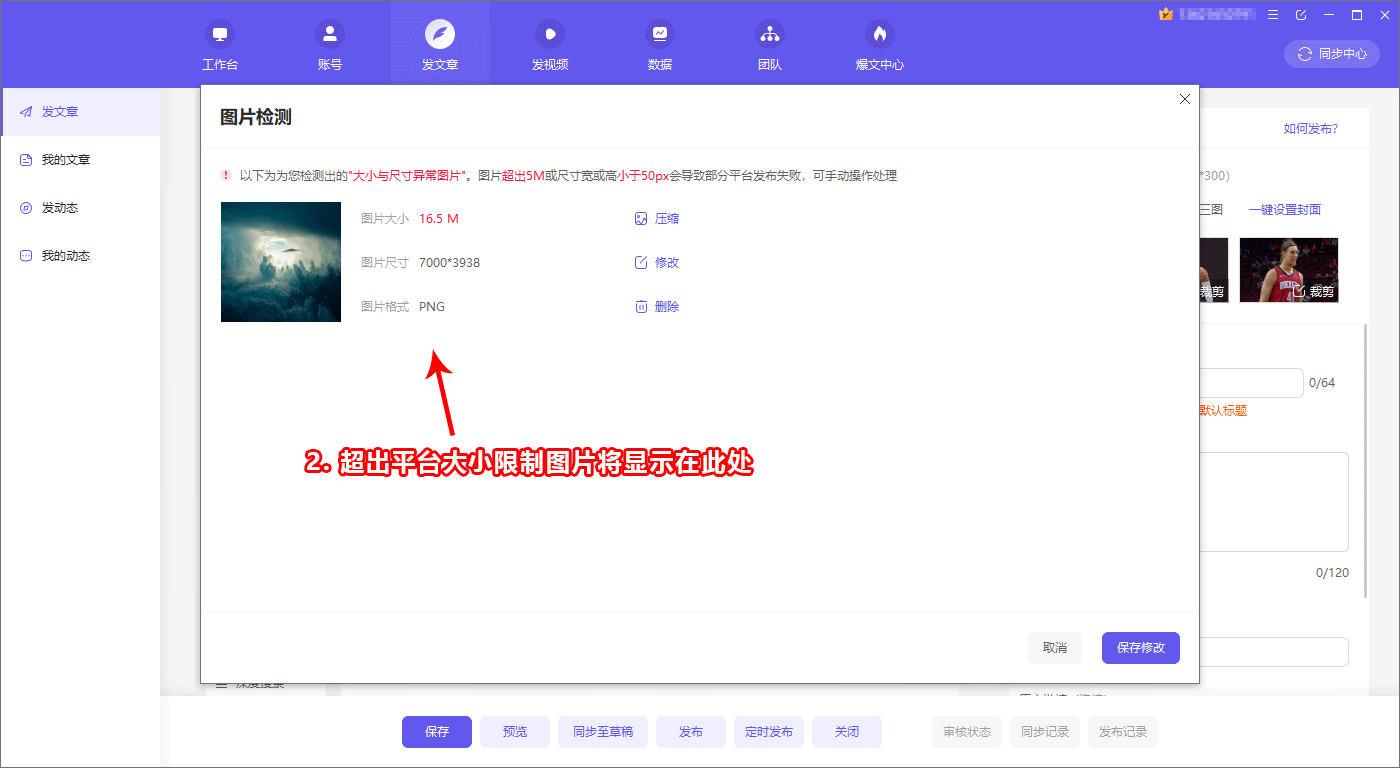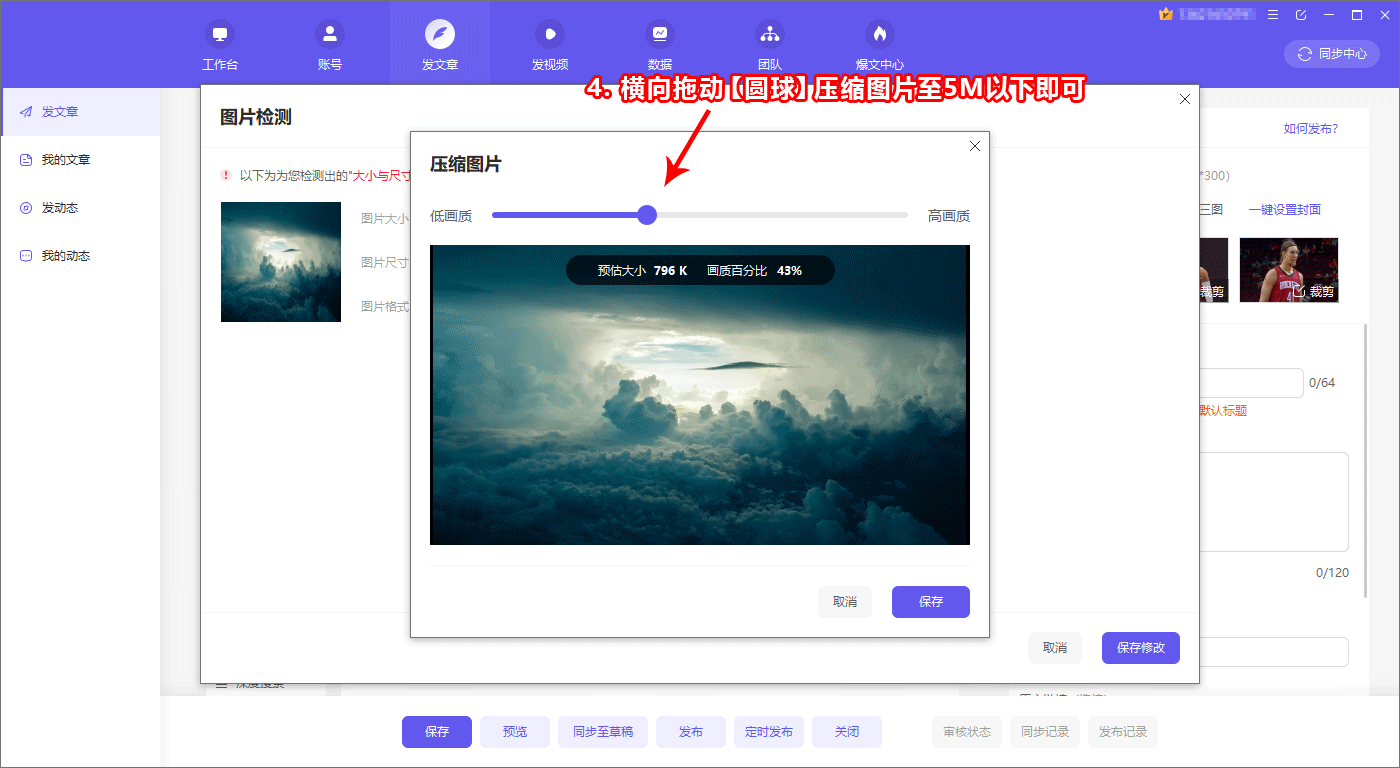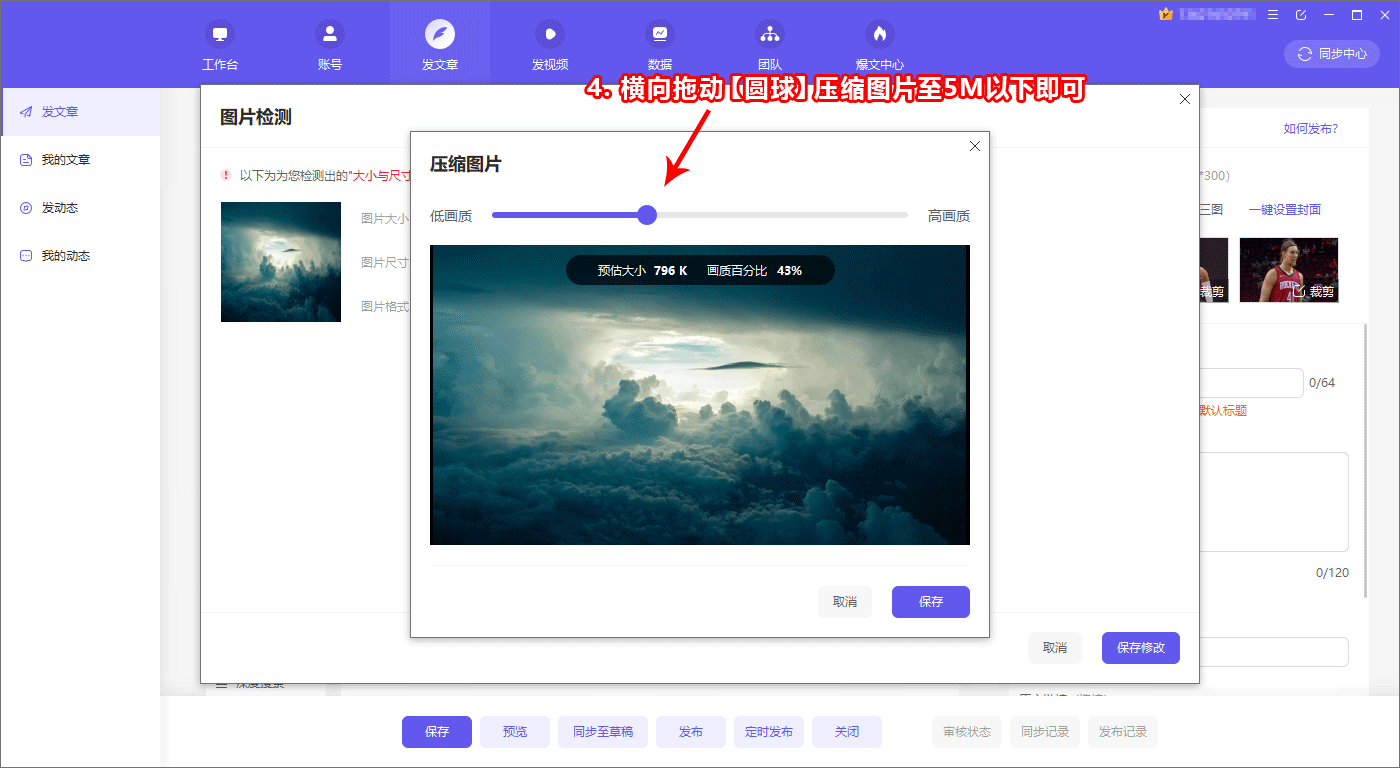
ÕüÜÕźĮµÉ£ńā”Õ╝ĢµōÄõ╝śÕī¢Õ┐ģķĪ╗õ║åĶ¦ŻÕģČÕĘźõĮ£ÕĤńÉå’╝łSEOÕ¤╣Ķ«ŁµĢÖń©ŗ1ÕQ?/h3>
µāø_üÜÕź?FONT color=#0000ff>µÉ£ńā”Õ╝ĢµōÄõ╝śÕī¢õĖĆÕ«ÜĶ”üõ║åĶ¦ŻµÉ£ńā”ÕĘźõĮ£ÕĤńÉåÕQ?B>Õ”éõĮĢµÅÉķ½śÕģ│ķö«Ķ»ŹµÄÆÕÉŹ’╝¤Õ”éõĮĢµÅÉÕŹćÕģ│ńø«µĀ浥üķćÅĶØ{Õī¢’╝¤õ║æĶÉźķöĆÕøóķś¤õĖ║µ?zh©©n)©Ķ«▓Ķ¦ŻµÉ£ńā”Õ╝ĢµōÄõ╝śÕī¢ÕĤńÉåŃĆéµÉ£ń┤óÕ╝ĢµōÄķ”¢Õģłµ┤ŠÕć║ŌĆ£Ķ£śĶøøŌĆØõ╗Äń┤óÕ╝ĢÕī║Õć║ÕÅæ’╝īÕ£©õ║ÆĶüöńĮæõĖŁµŖōÕÅ¢ńĮæÖÕĄ’╝īńäČÕÉĵöæųł░õĖ┤µŚČÕ║ōõĖŁÕQīÕ£©õĖ┤µŚČÕ║ōõĖŁŠ|æń½ÖĶŗźĶ┐śµ£ēÕģČõ╗¢ńÜäķōŠµÄźÕQīŌĆ£Ķ£śĶøøŌĆØõ╝ÜÖÕ║ńØĆķōŠµÄźśqøÕģźõĖŗõĖĆõĖ¬ķĪĄķØó’╝īÕåŹµŖŖśqÖõĖ¬ÖÕĄķØóµŖōÕÅ¢ÕłŅCÅ═(f©┤)µŚČÕ║ōõĖŁ’╝īśqÖµĀĘõĖŹµ¢ŁÕŠ¬ńÄ»ŃĆéõĮåõĖ┤µŚČÕ║ōõĖŁńÜäńĮæÖÕĄõ┐Īµü»õĖŹĮW”ÕÉłĶ¦äÕłÖÕQīÕ░▒Ķó½µĖģķÖżµÄēÕQøĶŗźĮW”ÕÉłĶ¦äÕłÖÕQīÕ░▒µöæųģźń┤óÕ╝ĢÕī║ŃĆéÕåŹķĆÜĶ┐ćÕłåń▒╗ŃĆüµĢ┤ńÉåŃĆüµÄÆÕ║ÅńŁēśqćń©ŗÕQīÕ░åĮW”ÕÉłĶ¦äÕłÖńÜäńĮæÖÕē|öŠÕłŅCĖ╗ń┤óÕ╝ĢÕī?/P>
ńÖæų║”µÉ£ńā”Õ╝ĢµōĵöČÕĮĢÖÕĄķØóõĖĆĶł¼µś»ķĆÜĶ┐ćńÖæų║”Ķ£śĶøøśqøĶĪīńł¼ÕÅ¢ÕÉÄńā”Õ╝ĢURLķōŠµÄźÕQīńäČÕÉÄÕ┼×µłÉÕ┐½ńģ¦Ķ┐øÕģźńÖŠÕ║”Õ┐½ńģ¦Õ║ōŃĆéĶ┐Öµś»ńÖŠÕ║”µÉ£ń┤óÕ╝Ģµōĵ£ĆÕ¤║ńĪĆńÜäÕĘźõĮ£’╝īĶĆīµÉ£ń┤óÕ╝ĢµōÄńÜäÕåģÕ«╣ķāĮµØźĶć¬ÕÉÄÕÅ░ńÜäÕ║×Õż¦ńÜäURLÕłŚĶĪ©ÕQīķĆÜĶ┐ćśqÖõ║øURLÕQīõĖŹµ¢ŁńÜäśqøĶĪīÕåģÕ«╣µöČÕĮĢÕQīÕé©ÕŁśŃĆüÕłåĶ»Źńā”Õ╝ĢÕÅŖŠl┤µŖżÕQīÕż¦Õ«ČÕŁ”õ╣?f©żn)µÉ£ń┤óÕ╝ĢµōĵöČÕĮĢńÜäŗ╣üń©ŗÕQīµöČÕĮĢÕĤńÉåÕÅŖµöČÕĮĢµ¢╣Õ╝ÅÕQīµ£ēµĢłńÜäµÅÉķ½śµÉ£ńā”Õ╝ĢµōÄÕ»╣ńĮæń½ÖńÜäµöČÕĮĢńÜäµĢ░ķćÅ’╝ü
õĖĆŃĆüķĪĄķØóµöČÕĮĢµĄüĮE?/B>
Õ£©õ║ÆĶüöńĮæõĖŁ’╝īURLµś»µ»ÅõĖ¬ķĪĄķØóńÜäÕģźÕÅŻÕ£░ÕØĆÕQīŌĆØĶ£śĶøøń©ŗÕ║ÅŌĆØķĆÜĶ┐ćśqÖõ║øURLÕłŚĶĪ©µŖōÕÅ¢Õł░ķĪĄķØóńÜäÕQīŌĆ£Ķ£śĶøøŌĆØõĖŹµ¢ŁńÜäõ╗ÄĶ┐Öõ║øķĪĄķØóõĖŁĶÄĘÕÅ¢URLĶĄäµ║ÉÕÅŖÕŁśÕé©ķĪĄķØó’╝ī“qČÕŖĀÕģźURLÕłŚĶĪ©ÕQīÕ”éµŁżõĖŹµ¢ŁńÜäÕŠ¬ńÄ»ÕQīµÉ£ń┤óÕ╝ĢµōÄÕ░▒ÕÅ»õ╗źõ╗Äõ║ÆĶüöńĮæõĖŁĶÄĘÕÅ¢Õł░Łæø_ż¤ńÜäķĪĄķØóŃĆéÕĮōńö©µłĘÕ£©µÉ£ń┤óÕ╝ĢµōÄõĖŁŗéĆń┤óõ┐Īµü»µŚČÕQīµÉ£ń┤óÕ╝ĢµōÄķ”¢Õģłµ┤ŠÕć║ŌĆ£Ķ£śĶøøŌĆØõ╗Äń┤óÕ╝ĢÕī║Õć║ÕÅæ’╝īÕ£©õ║ÆĶüöńĮæõĖŁµŖōÕÅ¢ńĮæÖÕĄ’╝īńäČÕÉĵöæųł░õĖ┤µŚČÕ║ōõĖŁÕQīÕ£©õĖ┤µŚČÕ║ōõĖŁŠ|æń½ÖĶŗźĶ┐śµ£ēÕģČõ╗¢ńÜäķōŠµÄźÕQīŌĆ£Ķ£śĶøøŌĆØõ╝ÜÖÕ║ńØĆķōŠµÄźśqøÕģźõĖŗõĖĆõĖ¬ķĪĄķØó’╝īÕåŹµŖŖśqÖõĖ¬ÖÕĄķØóµŖōÕÅ¢ÕłŅCÅ═(f©┤)µŚČÕ║ōõĖŁ’╝īśqÖµĀĘõĖŹµ¢ŁÕŠ¬ńÄ»ŃĆéõĮåõĖ┤µŚČÕ║ōõĖŁńÜäńĮæÖÕĄõ┐Īµü»õĖŹĮW”ÕÉłĶ¦äÕłÖÕQīÕ░▒Ķó½µĖģķÖżµÄēÕQøĶŗźĮW”ÕÉłĶ¦äÕłÖÕQīÕ░▒µöæųģźń┤óÕ╝ĢÕī║ŃĆéÕåŹķĆÜĶ┐ćÕłåń▒╗ŃĆüµĢ┤ńÉåŃĆüµÄÆÕ║ÅńŁēśqćń©ŗÕQīÕ░åĮW”ÕÉłĶ¦äÕłÖńÜäńĮæÖÕē|öŠÕłŅCĖ╗ń┤óÕ╝ĢÕī║’╝īõ╣¤Õ░▒µś»ńö©µł’L(f©źng)ø┤µÄźń£ŗÕł░µ¤źĶ»óńÜäŠlōµ×£ŃĆ?BR>
URLµś»ķĪĄķØóńÜäÕģźÕÅŻÕQīÕłÖÕ¤¤ÕÉŹÕłÖµś»Š|æń½ÖńÜäÕģźÕÅŻ’╝īµÉ£ńā”Õ╝ĢµōÄ׫▒µś»ķĆÜĶ┐ćÕ¤¤ÕÉŹśqøÕģźŠ|æń½ÖÕQīµī¢µÄśURLĶĄäµ║ÉÕQīµŹóĶĆīĶ©Ćõ╣ŗµÉ£ń┤óÕ╝ĢµōÄÕ£©õ║ÆĶüöŠ|æõĖŁµŖōÕÅ¢ÖÕĄķØóńÜäķ”¢Ķ”üõōQÕŖĪÕ░▒µś»Ķ”üµ£ēÕ║×Õż¦ńÜäÕ¤¤ÕÉŹÕłŚĶĪ©ÕQīÕ£©õĖŹµ¢ŁńÜäķĆÜĶ┐ćÕ¤¤ÕÉŹÕQīĶ┐øÕģźńĮæń½ÖµŖōÕÅ¢ńĮæń½ÖõĖŁńÜäķĪĄķØó’╝ī
ĶĆīÕ»╣õ║ÄÕÆ▒õ╗¼ĶĆīĶ©ĆÕQīµā│µÉ£ńā”Õ╝ĢµōĵöČÕĮĢÕQīķ”¢Ķ”üµØĪõ╗ČÕ░▒µś»ÕŖĀÕģźµÉ£ń┤óÕ╝ĢµōÄńÜäÕ¤¤ÕÉŹÕłŚĶĪ©ÕQīÕĖĖĶ¦üÕŖĀÕģźµÉ£ń┤óÕ╝ĢµōÄńÜäÕ¤¤ÕÉŹÕłŚĶĪ©ńÜäµ£ēõ╗źõĖŗõĖżń¦Źµ¢╣Õ╝Å
Õł®ńö©µÉ£ńā”Õ╝ĢµōĵÅÉõŠøńÜäńĮæń½ÖńÖ╗ÕĮĢÕģźÕÅŻ’╝īÕÉæµÉ£ń┤óÕ╝ĢµōĵÅÉõ║żńĮæń½ÖÕ¤¤ÕÉŹ’╝īõŠŗÕ”éńÖæų║”ńÜä’╝Ühttp://www.baidu.com/search/url_submit.htmlÕQīÕŻգ©µŁżµÅÉõ║żĶć¬ÕĘ▒ńÜäńĮæń½ÖÕ¤¤ÕÉŹ’╝īõĖŹĶ┐ćńö©µŁżµ¢ęÄ(gu©®)│ĢµÉ£ńā”Õ╝ĢµōÄÕŬõ╝Üիܵ£¤śqøĶĪīµŖōÕÅ¢“qȵø┤µ¢Ä═╝īśqÖń¦ŹÕüܵ│Ģµ»öĶŠāĶó½ÕŖ©ÕQīõ╗ÄÕ¤¤ÕÉŹµÅÉõ║żŠ|æń½ÖĶó½µöČÕĮĢĶŖ▒Ķ┤╣ńÜ䵌ēÖŚ┤õ╣¤µ»öĶŠāķĢ┐
ķĆÜĶ┐ćõĖĵ£ēĶ┤©ķćÅńÜäŌĆ£Õż¢ķōõÅĆØ’╝īõĮ┐µÉ£ń┤óÕ╝ĢµōÄÕ£©µŖōÕÅ¢ŌĆ£Õł½õ║║ŌĆØńÜäŠ|æń½ÖÖÕĄķØóµŚČÕÅæńÄ░µłæõ╗¼ńÜäŠ|æń½ÖÕQīõ╗ÄĶĆīÕ«×ńÄ░Õ»╣Š|æń½ÖńÜäµöČÕĮĢ’╝īśqÖń¦Źµ¢ęÄ(gu©®)│ĢõĖšdŖ©µØāÕ£©µłæõ╗¼µēŗõĖŖÕQī’╝łÕŬĶ”üµłæõ╗¼µ£ēĶā÷Õż¤ÕżÜńÜäŌĆ£Õż¢ķōõÅĆØ’╝ēõĖöµöČÕĮĢķƤÕ║”µ»öń¼¼õĖĆ┐UŹµ¢╣µ│ĢÕ┐½ÕQīµĀ╣µŹ«Õż¢ķā©ķōŠµÄźńÜäµĢ░ķćÅŃĆüĶ┤©ķćÅńøĖÕģŽxƦ’╝īõĖĆĶł?-7Õż®Õ░▒õ╝ÜĶó½µÉ£ńā”Õ╝ĢµōĵöČÕĮĢ
õ║?ÖÕĄķØóµöČÕĮĢÕĤńÉå
ķĆÜĶ┐ćÕŁ”õ╣Ā(f©żn)ŌĆ£ķĪĄķØóµöČÕĮĢµĄüĮEŗŌĆØÕÅ»õ╗źµÄīµÅĪÕŖĀÕ┐½ńĮæń½ÖĶó½µöČÕĮĢńÜäµ¢╣µ│Ģ’╝īµÄźńØĆµØźÕŁ”õ╣?f©żn)ķĪĄķØóµöČÕĮĢÕĤńÉå’╝īõ╗ÄĶĆīµÅÉķ½śµÉ£ń┤óÕ╝ĢµōĵöČÕĮĢńÜäµĢ░ķćÅÕQ?BR>
Õ”éµ×£µŖŖõĖĆõĖ¬ńĮæń½ÖķĪĄķØóń╗䵳ÉńÜäÖÕĄķØóń£ŗÕüܵś»õĖĆõĖ¬µ£ēÕÉæÕøŠÕQīõ╗ĵīćÕ«ÜńÜäķĪĄķØóÕć║ÕÅæ’╝īµ▓┐ńØĆÖÕĄķØóõĖŁńÜäķōŠµÄźÕQīµīēńģ¦µ¤É┐UŹńē╣Õ«ÜńÜäĮ{¢ńĢźÕ»╣ńĮæń½ÖõĖŁńÜäķĪĄķØóĶ┐øĶĪīķüŹÕÄåŃĆéõĖŹÕü£Õ£░õ╗ÄURL ÕłŚĶĪ©õĖŁń¦╗Õć║ÕĘ▓ŠlÅĶ«┐ķŚ«ńÜäURLÕQīÕŲłÕŁśÕé©ÕĤզŗÖÕĄķØóÕQīÕÉīµŚČµÅÉÕÅ¢ÕĤզŗķĪĄķØóõĖŁńÜäURLńÜäõ┐Īµü»’╝ÜÕåŹÕ░åURLÕłåõžōÕ¤¤ÕÉŹÕÅŖÕåģķā©URLõĖżÕż¦Šc╗’╝īÕÉīµŚČÕłżµ¢ŁURLµś»ÕÉ”Ķó½Ķ«┐ķŚ«Ķ┐ćÕQ?׫嵣¬Ķ«ēKŚ«śqćńÜäURLÕŖĀÕģźURLÕłŚĶĪ©õĖŁŃĆéķĆÆÕĮÆÕ£░µē½µÅÅURLÕłŚĶĪ©ÕQīńø┤ĶćīÖĆŚÕ░ĮµēƵ£ēURLĶĄäµ║ÉõĖ║µŁóŃĆéń╗ÅśqćĶ┐Öõ║øÕĘźõĮ£’╝īµÉ£ńā”Õ╝ĢµōÄ׫▒ÕÅ»õ╗źÕŠÅń½ŗÕ║×Õż¦ńÜäÕ¤¤ÕÉŹÕłŚĶĪ©ŃĆüķĪĄķØóURL ÕłŚĶĪ©“qČÕé©ÕŁśĶā÷Õż¤ÕżÜńÜäÕĤզŗķĪĄķØóŃĆ?BR>
õĖēŃĆüķĪĄķØóµöČÕĮĢµ¢╣Õ╝?/FONT>
ń¤źķüōõ║?ŌĆ£ķĪĄķØóµöČÕĮĢµĄüĮEŗŌĆØÕÆīŌĆ£ķĪĄķØóµöČÕĮĢÕĤńÉåŌĆ?ńäČĶĆīÕ£©µÉ£ńā”Õ╝ĢµōÄõĖŁĶ”üĶÄĘÕÅ¢ńøĖÕ»╣ķćŹĶ”üÖÕĄķØóÕQīÕ░▒µČēÕÅŖÕłŅC║åµÉ£ńā”Õ╝ĢµōÄńÜäķĪĄķØóµöČÕĮĢµ¢╣Õ╝Å’╝ī
ÖÕĄķØóµöČÕĮĢµ¢╣Õ╝ŵś»µīćµÉ£ńā”Õ╝ĢµōĵŖōÕÅ¢ÖÕĄķØóµŚČµēĆõĮ┐ńö©ńÜäńŁ¢ńĢź’╝īńø«ńÜ䵜»õžōõ║åĶāĮÕ£©õ║ÆĶüöńĮæõĖŁńŁøķĆēÕć║ńøĖÕ»╣ķćŹĶ”üńÜäõ┐Īµü»’╝īÖÕĄķØóµöČÕĮĢńÜäµ¢╣Õ╝ÅńÜäÕłČÕ«ÜÕÅ¢Õå│õ║ĵɣń┤óÕ╝ĢµōÄÕ»╣Š|æń╗£Šlōµ×äńÜ?ńÉåĶ¦ŻŃĆéÕ”éµ×£õŗ╔ńö©ńøĖÕÉīńÜäµŖōÕÅ¢Į{¢ńĢźÕQīµÉ£ń┤óÕ╝ĢµōÄÕ£©ÕÉīµĀĘńÜ䵌ČķŚ┤ÕåģÕÅ»õ╗źÕ£©µ¤ÉõĖĆŠ|æń½ÖõĖŁµŖōÕÅ¢Õł░µø┤ÕżÜńÜäķĪĄķØóĶĄäµ║É’╝īÕłÖõ╝ÜÕ£©Ķ»źŠ|æń½ÖÕü£ńĢÖµø┤ķĢ┐ńÜ䵌ČķŚ▀_╝īµöČÕĮĢńÜäķĪĄķØóµĢ░Ķć¬ńäČõ╣¤Õ░▒ÕżÜõ║åŃĆ?ÕøĀµŁżÕQīÕŖĀµĘ▒Õ»╣µÉ£ńā”Õ╝ĢµōÄÖÕĄķØóµöČÕĮĢµ¢╣Õ╝ÅńÜäĶ«żĶ»å’╝īµ£ēÕł®õ║ÄõžōŠ|æń½ÖÕ╗║ń½ŗÕÅŗÕźĮńÜäń╗ōµ×ä’╝īµÅÉķ½śĶó½µöČÕĮĢńÜäµĢ░ķćÅŃĆ?BR>µÉ£ńā”Õ╝ĢµōĵɣµöČÕĮĢķĪĄķØóńÜäµ¢╣Õ╝ÅõĖ╗Ķ”üĶ”üµ£ēŌĆ£Õ╣┐Õ║”õ╝śÕģłŌĆØŃĆüŌĆ£µĘ▒Õ║”õ╝śÕģłŌĆ£ÕÅŖŌĆØńö©µłõhÅÉõ║żŌĆ£’╝łńö©µłĘµÅÉõ║żµÜ鵌ČõĖŹĶ«▓ÕQēõĖē┐UŹ’╝īĶ«żĶ»åśqÖõĖē┐UŹķĪĄķØóµöČÕĮĢµ¢╣Õ╝ÅÕÅŖÕÉäĶć¬ńÜäõ╝śŠ~║ńé╣ÕQ?BR>
A:“q┐Õ║”õ╝śÕģł
Õ”éµ×£µŖŖµĢ┤õĖ¬ńĮæń½Öń£ŗÕüÜõĖĆŗéē|Āæ(w©©i)ÕQīķ”¢ÖÕĄÕ░▒µś»µĀ╣ÕQīµ»ÅõĖ¬ķĪĄķØóÕ░▒µś»ÕÅČÕŁÉŃĆéÕ╣┐Õ║”õ╝śÕģłµś»õĖĆ┐UŹµ©¬ÕÉæńÜäÖÕĄķØóµŖōÕÅ¢µ¢╣Õ╝ÅÕQīÕģłõ╗ĵĀæ(w©©i)ńÜäĶŠāŗ╣ģÕ▒éÕ╝ĆÕ¦ŗµŖōÕÅ¢ķĪĄķØó’╝īńø┤µÄźµŖōÕ«īÕÉīÕ▒éŗŲĪńÜäµēƵ£?ÖÕĄķØóÕÉĵēŹśqøÕģźõĖŗõĖĆÕ▒éŃĆéÕøĀµŁż’╝īÕ£©Õ»╣Š|æń½ÖśqøĶĪīõ╝śÕī¢µŚė×╝īµłæõ╗¼Õ║öĶ»źµŖŖńĮæń½ÖńøĖÕ»ÜwćŹĶ”üńÜäõ┐Īµü»Õ▒Ģńż║Õ£©Õ▒éŗŲĪµ»öĶŠāµĄģńÜäķĪĄķØóõĖŖÕQłõŠŗÕ”é’╝ÜÕ£©ķ”¢ÖÕē|Ä©ĶŹÉõĖĆõ║øńāŁķŚ©ńÜäÕåģÕ«╣ÕQēŃĆéÕÅŹśqćµØźÕQīķĆ?śqćÕ╣┐Õ║”õ╝śÕģłńÜäµŖōÕÅ¢µ¢╣Õ╝ÅÕQīµÉ£ń┤óÕ╝ĢµōÄÕ░▒ÕÅ»õ╗źķ”¢ÕģłµŖōÕÅ¢Õł░ńĮæń½ÖõĖŁńøĖÕ»╣ķćŹĶ”üńÜäķĪĄķØóŃĆ?BR>ķ”¢ÕģłÕQīŌĆØĶ£śĶøøŌĆ£õ╗ÄŠ|æń½ÖńÜäķ”¢ÖÕĄÕć║ÕÅæ’╝īµŖōÕÅ¢ķ”¢ķĪĄõĖŖµēƵ£ēĶ┐׵ğµīćÕÉæńÜäÖÕĄķØóÕQīÕ┼×µłÉķĪĄķØóķøåÕÉłAÕQīÕŲłÕłåµ×ÉÕć║AõĖŁµēƵ£ēķĪĄķØóõĖŁńÜäķōŠµÄź’╝ÜÕ£©ĶʤĒt¬Ķ┐Öõ║øķōŠµÄźµŖōÕÅ¢õĖŗõĖĆÕ▒éńÜäÖÕĄķØóÕQīÕ┼×µłÉķĪĄķØóķøåÕÉłBÕQÜÕ░▒śqÖµĀĘķĆÆÕĮÆÕ£ŅC╗Äŗ╣ģÕ▒éÖÕĄķØóõĖŁĶ¦Żµ×ÉÕć║ķōŠµÄźÕQīÕåŹõ╗ĵĘ▒Õ▒éķĪĄķØó’╝īńø┤Ķć│µ╗ĪĶā÷µ¤ÉõĖ¬Ķ«æų«ÜńÜäµØĪõ╗ȵēŹÕü£µŁóµŖōÕÅ¢śqøń©ŗ
B:µĘ▒Õ║”õ╝śÕģł
õĖÄÕ╣┐Õ║”õ╝śÕģłńÜäµŖōÕÅ¢µ¢╣Õ╝ÅńøĖÕÅŹÕQīµĘ▒Õ║”õ╝śÕģłķ”¢ÕģłĶʤĒt¬µĄģÕ▒éķĪĄķØóõĖŁńÜ䵤ÉõĖĆśq׵ğÕÉÄķĆɵŁźµŖōÕÅ¢µĘ▒Õ▒éÖÕĄķØóÕQīńø┤ĶćŽxŖōÕ«īµ£ĆµĘ▒Õ▒éńÜäķĪĄķØóµēŹśqöÕø×ŗ╣ģÕ▒éÖÕĄķØóÕåŹĶʤĒt¬ÕģČÕÅ”õĖĆķōŠµÄźÕQīń涊l?ÕÉæµĘ▒Õ▒éķĪĄķØóµŖōÕÅ¢’╝īśqÖµś»õĖĆ┐UŹń║ĄÕÉæńÜäÖÕĄķØóµŖōÕÅ¢µ¢╣Õ╝ÅŃĆéõŗ╔ńö©µĘ▒Õ║”õ╝śÕģłńÜäµŖōÕÅ¢µ¢╣Õ╝ÅÕQīµÉ£ń┤óÕ╝ĢµōÄÕÅ»õ╗źµŖōÕÅ¢Õł░Š|æń½ÖõĖŁĶŠāõĖ║ķÜÉĶöĮŃĆüÕåĘķŚ©ńÜäÖÕĄķØóÕQīĶ┐ÖµĀĘÕ░▒ĶāĮµ╗ĪŁæŽxø┤ÕżÜńö©µł’L(f©źng)Üäķ£Ćµ▒éŃĆ?BR>
ķ”¢ÕģłÕQīµÉ£ń┤óÕ╝ĢµōÄõ╝ܵŖōÕÅ¢Š|æń½ÖńÜäķ”¢ÖÕĄ’╝ī“qȵÅÉÕÅ¢ķ”¢ÖÕĄõĖŁńÜäķōŠµÄź’╝ÜÕåŹµ▓┐ńØĆÕģČõĖŁńÜäõĖĆõĖ¬Ķ┐׵ğµŖōÕÅ¢Õł░ÖÕĄķØó A-1ÕQīÕÉīµŚČĶÄĘÕÅ¢A-1õĖŁńÜäķōŠµÄź“qȵŖōÕÅ¢ķĪĄķØóB-1ÕQīĶÄĘÕÅ¢B-1õĖŁńÜäµØźķōŠµÄźÕŲłµŖōÕÅ¢ÖÕĄķØóC-1 ÕQīÕ”éµŁżõĖŹµ¢ŁńÜäķćŹÕżŹÕQīµ╗ĪŁæø_ł░µ¤ÉõĖ¬µØĪõÜgÕÉÄ’╝īÕåŹõ╗ÄA-2µŖōÕÅ¢ÖÕĄķØóÕÅŖķōŠµÄź’╝ü
ÕåģÕ«╣µÅÉĶ”üÕQ?BR>
Õø?µÉ£ńā”Õ╝ĢµōÄÕ”éõĮĢķü┐ÕģŹķćŹÕżŹµĆ¦µöČÕĮ?BR>
ŌæĀµÉ£ń┤óÕ╝ĢµōÄĶØ{ĶĮĮķĪĄķØóńÜäÕłżµ¢Ł
ŌæĪµÉ£ń┤óÕ╝ĢµōÄķĢ£ÕāÅķĪĄķØóÕłżµ¢?BR>
õ║?ÖÕĄķØóŠl┤µŖżµ¢╣Õ╝Å
ŌæĀիܵ£¤µŖōÕÅ?BR>
ŌæĪÕó×ķćŵŖōÕÅ?BR>
ŌæóÕłåŠcšd«ÜõĮŹµŖōÕÅ?BR>
Õģ?ÖÕĄķØóÕé©ÕŁś